
Abstract
PURPOSE Patient ratings of physician’s patient-centered communication are used by various specialty credentialing organizations and managed care organizations as a measure of physician communication skills. We wanted to compare ratings by real patients with ratings by standardized patients of physician communication.
METHODS We assessed physician communication using a modified version of the Health Care Climate Questionnaire (HCCQ) among a sample of 100 community physicians. The HCCQ measures physician autonomy support, a key dimension in patient-centered communication. For each physician, the questionnaire was completed by roughly 49 real patients and 2 unannounced standardized patients. Standardized patients portrayed 2 roles: gastroesophageal disorder reflux symptoms and poorly characterized chest pain with multiple unexplained symptoms. We compared the distribution, reliability, and physician rank derived from using real and standardized patients after adjusting for patient, physician, and standardized patient effects.
RESULTS There were real and standardized patient ratings for 96 of the 100 physicians. Compared with standardized patient scores, real-patient–derived HCCQ scores were higher (mean 22.0 vs 17.2), standard deviations were lower (3.1 vs 4.9), and ranges were similar (both 5–25). Calculated real patient reliability, given 49 ratings per physician, was 0.78 (95% confidence interval [CI], 0.71–0.84) compared with the standardized patient reliability of 0.57 (95% CI, 0.39–0.73), given 2 ratings per physician. Spearman rank correlation between mean real patient and standardized patient scores was positive but small to moderate in magnitude, 0.28.
CONCLUSION Real patient and standardized patient ratings of physician communication style differ substantially and appear to provide different information about physicians’ communication style.
INTRODUCTION
Patient-centered care is a core dimension of health care quality, and strong communication skills are required to ensure such care.1 Yet, policy makers and researchers do not know how best to measure these physician communication skills.2 Because patient ratings of physician communication from surveys have face validity and are readily available, they are widely used by such organizations as the American Board of Internal Medicine and various managed care organizations.3 These ratings may eventually be used for specialty recredentialing and to determine physician bonus payments.
Patient ratings of physicians are subject to a number of limitations, however. These limitations include potential biases from survey nonresponse, patient selection (and deselection) of the physician, patient accommodation to the physician’s style with time,4 length of relationship, different patient complaints, and ceiling effects.5 Patients also respond in a global manner when rating their physicians, with high correlations among scales measuring different behaviors and constructs.4,6 Patient rating of physician communication, but not technical quality, is a key predictor of patient global satisfaction.7
Standardized patients—persons trained to portray a specific patient case in a standardized fashion8—represent a potentially more objective means for assessment of physician communication. Standardized patients can be trained to rate physician-patient communications skills reliably9,10 and are used by medical schools and the US Medical Licensure Examination to assess competence.8,11,12 Unannounced standardized patients have also been used in research to rate community physicians’ history taking, physical examination, medical decision making, and communication, as well as health services utilization and quality of care.13–18 They have been regarded by some as the reference standard for assessing physician performance,19 but their use in assessing communication is still evolving. In addition to assessing specific behaviors, standardized patients can also provide their subjective impression of physicians. Their training and exposure to multiple physicians allows standardized patients to act as connoisseurs of clinical care.20
To better understand the strengths and limitations of real patient and standardized patient assessment techniques, we sought to compare standardized patient ratings with real patient ratings of physicians’ patient-centered communication. Specifically, we compared the distribution of scores on identical scales completed by real patients and standardized patients, assessed the correlation between real and standardized patient ratings, and contrasted differences in rank order using these 2 assessment methods. We used an adaptation of the Health Care Climate Questionnaire (HCCQ) to assess communication. The HCCQ is designed to assess a key component of physician communication, that is, the extent to which the patient perceives the physician as supporting patient autonomy in decision making.21
METHODS
We compared perceptions of primary care physicians’ patient-centered communication from 2 sources: (1) standardized patient ratings, 2 encounters per physician; and (2) real patient ratings, completed by about 49 patients of each physician. Real patients also provided information regarding their sociodemographic characteristics, health status, and duration of their relationship with their physician. Full details regarding the study are provided elsewhere.4,17,22
Physician Sample
In 1999, we identified 594 primary care physicians (internists and family physicians) in active clinical practice within 45 minutes’ drive of Rochester, NY, who belonged to a large managed care organization (MCO) serving the 8-county Rochester, region (population 1.1 million). To achieve stable measures of performance indicators, only the 506 physicians who had more than 100 MCO patients were eligible; thus, enrolled physicians had larger practices than nonenrolled physicians. A maximum of 2 physicians per practice were recruited to avoid clustering effects and to minimize physician detection of standardized patients. In all, 297 physicians were personally contacted by 12 physician-recruiters in random order until a total of 100 physicians were recruited. Of the 297 physicians identified for recruitment, 109 (37%) refused to participate, and 14 were ineligible. Analyses of MCO claims data showed that the patient and utilization characteristics among participating and nonparticipating practices were similar.
Physicians gave informed consent to participate in a study of “patient care and outcomes.” They agreed to have 2 unannounced, covertly audio-recorded standardized patient visits within the subsequent 12 months (2000–2001). Physicians were reimbursed $100 for each standardized patient visit (including administration of waiting room patient questionnaires); $100 was also provided to the office staff for their assistance. The study received institutional review board approval from the University of Rochester and local hospitals.
Standardized Patient Roles
We developed standardized patient roles to provide physicians with identical clinical scenarios and to avoid potential rating biases with real patients. A physician community advisory panel suggested that using more than 2 standardized patients per physician would likely compromise physician recruitment. Thus, during the 2000–2001 period, each participating physician had visits from 2 standardized patients, portraying 1 of 2 roles. The 2 roles were selected to contrast physicians’ responses to real patients who had straightforward symptoms with those who reported ambiguous or medically unexplained symptoms. The straightforward role involved a patient with symptoms typical of gastroesophageal reflux disorder (GERD) or heartburn, complaining of nocturnal chest pain exacerbated by food and partially relieved by antacids, and with minimal emotional distress. The ambiguous symptoms role involved a patient with symptoms characteristic of multisomatoform disorder: multiple symptoms, poorly characterized chest pain, and moderate emotional distress.23 During pilot testing, the roles were calibrated to avoid prompting referral to an emergency department or administration of medications while in the physician’s office. Five middle-aged, nonobese, white standardized patients (2 men, 3 women) were used in the study. Each physician saw 1 male and 1 female standardized patient, and 1 of each role (2 female standardized patients were needed for the GERD role, as 1 standardized patient could not complete all visits in the study; each standardized patient made at least 25 visits). The first standardized patient visit was randomized by illness condition and sex.
Standardized Patient and Real Patient Survey Data
We use the HCCQ, based on self-determination theory,21 to assess patient-centered communication. The HCCQ assesses physician support for patient autonomy. Autonomy support is associated with improved patient adherence, outcomes, and satisfaction, and is a critical element of patient-centered communication.24–27 Items in the scale include judgments about whether the physician provided patients with options about their health, conveyed confidence to them in their ability to make changes important for their health, and tried to understand their perspectives before suggesting medical or behavioral changes. Items also assess whether the patient felt understood by the physician, and whether the physician encouraged the patient to ask questions. The modified 5-item version of the HCCQ uses a 5-point Likert scale (1 = strongly disagree and 5 = strongly agree) to rate physician behavior, with a score range of 5 (low support) to 25 (high support).
After each encounter, the standardized patient completed the HCCQ. Cronbach’s α for the scale, as reported by the standardized patients, was 0.92.
About 50 consecutive real patients aged 18 to 65 years were approached by a research assistant in each of the primary care physician’s waiting room to complete a questionnaire before their office visit. The questionnaire included the HCCQ and questions on demographics (age, sex, race/ethnicity, and years of schooling), health status (a checklist of chronic disease conditions), the Medical Outcomes Study Short Form 12-item survey (SF-12),28 and duration (years) of the patient’s relationship with the physician. Cronbach’s α for the HCCQ scale, as reported by real patients, was also 0.92.
About halfway through our project, a new instrument became available for patients to assess their perception of the physician’s patient-centeredness during office visits. This instrument, called the Patient Perception of Patient-Centeredness (PPPC) was developed by Stewart et al.29 It comprises 14 Likert-scale items, each with a 4-point scale. Standardized patients and real patients completed the PPPC measure immediately after their visit with participating physicians. The PPPC measure was scaled from a minimum of 14 (least patient-centered) to 56 (most patient-centered). The Cronbach’s α for the 14-item postvisit PPPC scale in patients was 0.90. We examined the physician ρ statistic for both real and standardized patients for the PPPC, and also compared real and standardized patient scores for the HCCQ and PPPC.
Statistical Analyses
Data were analyzed using Stata (Version 9.2, StataCorp, College Station, Tex), and analyses were adjusted for the nesting of standardized and real patient observations by physician. We conducted 2 sets of random intercept, mixed-effects regression analyses with the HCCQ scores as dependent variables and the physicians as independent random effects. In the standardized patient analyses, the other independent variables included role (GERD vs ambiguous chest pain) and a dummy variable for each standardized patient (to adjust for systematic differences in standardized patient scoring unrelated to the physician effects). In the real patient analyses, the other independent variables included factors that might bias patients’ assessment of physician interpersonal style (demographics, health status, and relationship length). We did not include physician, physician practice, or health system factors, because these variables were similarly experienced by real and standardized patients. Assessment of the physician random effects (or variance components) allowed (1) calculation of the interrater reliability of the standardized patients’ and real patients’ assessment of HCCQ scores, and (2) assessment of the physicians’ predicted effects on HCCQ scores. We report the reliability based on the proportion of total variance contributed by the physician variance component (ρ, an intraclass correlation coefficient).30 In turn, the predicted reliability, a function of the number observations, is derived from the intraclass correlation coefficient using the Spearman-Brown prophecy formula:
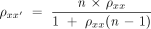
Here, ρxx′ is predicted (or desired) reliability, n is the number of observations, and ρxx is observed intra-class correlation coefficient (observed reliability) from our study. The predicted effects of the physicians on the patient-centered communication score, as derived using a random effects model, is known as the best linear unbiased prediction. Key advantages of the random effects model compared with a fixed dummy variable approach to assessing physician performance include allowing inferences based on the total possible universe of samples (beyond the predicted effects just based on the specific physicians and raters sampled), and adjustment for the variable uncertainty in the predicted effects caused by differing amounts of information about each physician (for example, the number of raters).30 We explore the shared variance between real and standardized patient ratings of physicians, based on their Pearson product moment correlations, and the differences in how they ranked physicians using Spearman rank order correlations. Ranking was based on standardized-patient–derived postvisit HCCQ scores and real-patient–derived previsit scores.
RESULTS
Of the 100 physicians, 93 completed both standardized patient visits, and 7 completed only 1 visit because of retirement or relocation; no other physician withdrew from the study. The physicians had a mean age of 45 years and were predominantly male; most were in a group practice and in a nonrural location (Table 1⇓). A total of 4,746 patients (96% of those approached) were enrolled and completed the previsit questionnaire. In all, questionnaires were completed by patients for 96 of the 100 physicians. Enrolled patients were modally female, white, had at least some college education, and at least a 5-year relationship with their physician (Table 2⇓). Complete HCCQ and demographic data were available for approximately 49 patients per physician. For the patient-centered communication postvisit subset, we obtained data from 1,730 patients of 57 doctors, with the same eligibility criteria and methods as the previsit questionnaires.
Characteristics of Physicians in Sample (N = 100)
Characteristics of Real Patients in the Sample
Real patient HCCQ scores were skewed toward favorable physician ratings. The mean patient HCCQ score was 22.0 (of a possible 25), with a standard deviation 3.1, and a range 5 to 25. The unannounced standardized patient scores were more normally distributed. Their mean HCCQ score was lower (17.25), and the standard deviation was greater (4.9), but with a similar range (5–25).
Adjusting for real patient demographics, health status, and length of relationship, the physician ρ for autonomy support based on real patient ratings was 0.07 (95% confidence interval [CI], 0.05–0.108; P <.001). Using the Spearman-Brown prophecy formula, based on an average of 49 real patients per physician, the patient-based physician ρ translates into a reliability of 0.78 (95% CI, 0.71–0.84). To reach a desired reliability of 0.9, ratings from 120 patients (95% CI, 75–180) would be required. After adjustment for standardized patient and case, the physician ρ for autonomy support based on standardized patient ratings was 0.40 (95% CI, 0.24–0.58; P <.001). Using the Spearman-Brown prophecy formula, based on 2 observations per physician, the standardized-patient–based physician ρ translates into a reliability of 0.57 (95% CI, 0.39–0.73). To reach a desired reliability of 0.9, ratings from 14 standardized patients (95% CI, 7–29) would be required.
The Pearson product moment correlation between the real-patient– and standardized-patient–derived, best, linear, unbiased predicted physician scores was 0.30, which, when squared, yields the shared variance, 9%. The maximum possible correlation, given the imperfect standardized and real patient reliability, is the square root of the product of their reliabilities (or 0.67). Thus, the adjusted correlation, given perfect reliability, would be 0.47. In other words, the maximum shared variance between the 2 sets of scores is 22%. The relationship between the 2 sets of scores is shown in Figure 1⇓. As can be seen, standardized patient and real patient rankings were quite different, with a Spearman rank order correlation of 0.28.
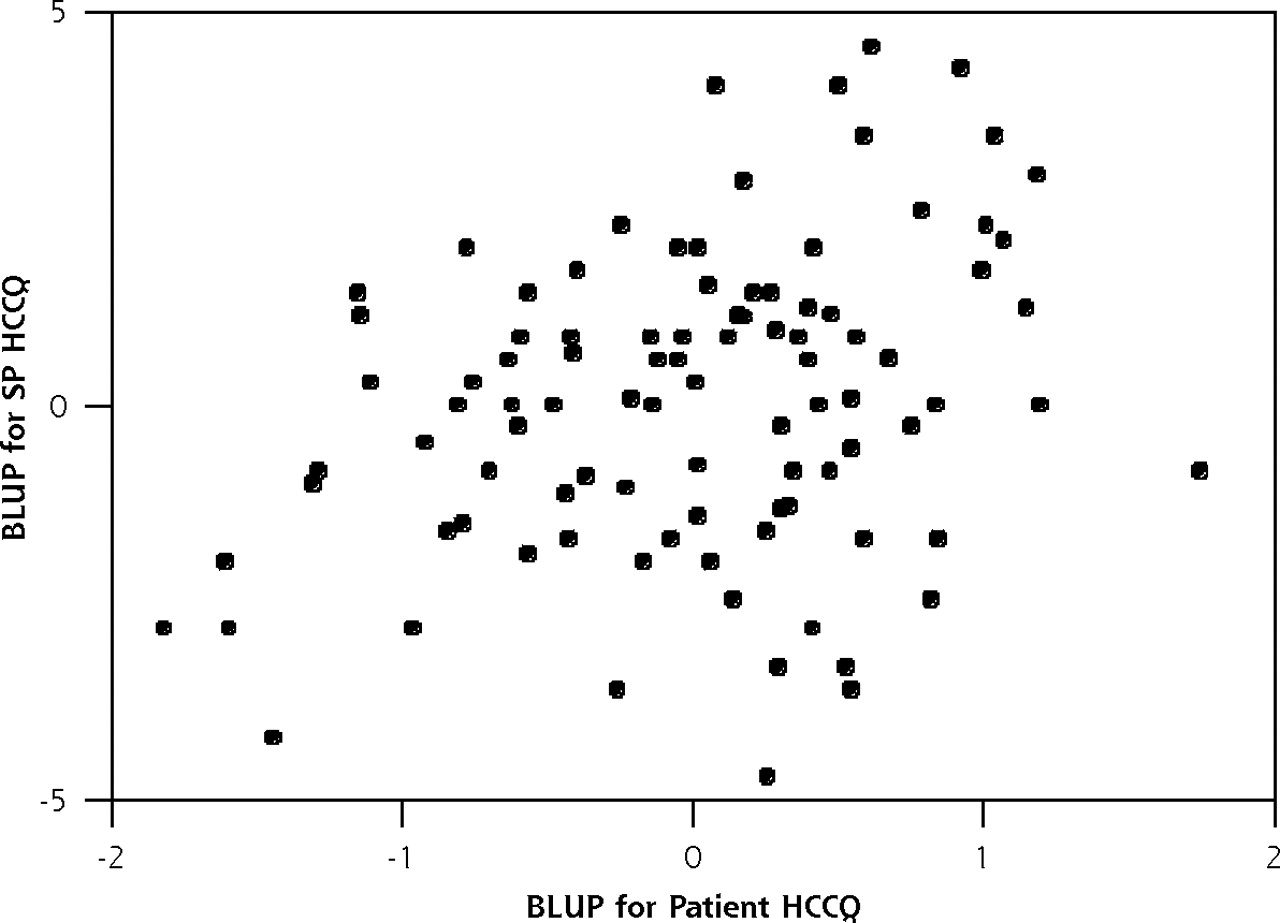
Relationship between adjusted standardized patient and real patient ratings of physicians.
BLUP = best linear unbiased prediction; SP = standardized patient; HCCQ = Health Care Climate Questionnaire.
For the 57 physicians on whom postvisit PPPC ratings were obtained, the mean PPPC score for real patients was higher, 51.5 (SD 5.7; range, 19–56), than that for standardized patients, 38.2 (SD 9.2; range, 19–55). After adjustment for standardized patient and case, the physician ρ for PPPC based on standardized patient ratings was 0.40 (95% CI, 0.21–0.63; P <.001). Adjusting for patient demographics, health status and length of relationship, the physician ρ for PPPC based on real patient ratings was 0.06 (95% CI, 0.03–0.09; P <.001). The correlations among the physician-level mean HCCQ and PPPC scores by real and standardized patients are shown in Table 3⇓.
Correlations Among the Physician-Level Mean HCCQ and PPPC Scores Obtained From Real Patients and Standardized Patients
DISCUSSION
Although there is no external standard by which to judge the relative validity of either real or standardized patient ratings, unannounced standardized patient ratings of physician communication skills show superior psychometric properties. In contrast to real patient ratings, standardized patient ratings were more normally distributed and showed greater variation. The proportion of total variance contributed by the physician variance component was much greater for standardized than real patient ratings. As a result, a single postvisit standardized patient rating is far more reliable than a single real patient self-report, either before or after a clinic visit. The low correlations and differences in outliers show that real and standardized patient rating ratings yield quite different rankings of physicians for autonomy support. These correlations, using a sample of community physicians, are somewhat lower than those observed in a similarly designed study of 26 Canadian resident physicians.31 In that study, an adjusted correlation of 0.51 was observed between standardized patient and real patient ratings using the American Board of Internal Medicine satisfaction scale.
The HCCQ data were obtained after the standardized patient encounter and before the real patient encounter, whereas the PPPC data were obtained after the encounter for both standardized and real patients. Despite these methods differences, the results for the HCCQ and PPPC closely parallel each other. Thus, for the standardized patients, mean PPPC scores were lower and standard deviations were higher than observed for real patients. Further, for both real and standardized patient evaluations, the physician ρ for the PPPC scores was quite similar to the physician ρ obtained for the HCCQ; and for both PPPC and HCCQ, the physician ρ was much higher for standardized patient evaluations than for real patient evaluations. The high correlations between the standardized patient HCCQ and PPPC scales (0.89) suggest that both scales measure a similar underlying construct. This observation is consistent with previous work6 suggesting that when assessing physicians along nominally different dimensions, patients tend to make a global, or halo, assessment; thus, at the physician level, substantive distinctions among the constructs may not be critical. Despite data being obtained before (HCCQ) and after (PPPC) the encounter, the correlations between the 2 patient-scored scales were also high (0.74).
For both scales, the standardized and real patient correlations were modest (between 0.26 and 0.33). The low correlation in physician ranking based on real and standardized patient ratings suggest caution in using only real patient ratings for pay-for-performance or recredentialing. Different physicians would be rewarded for their interpersonal skills depending on which measurement approach is used. These findings, combined with those from studies suggesting that associations between patient ratings and patient report of health status and other outcomes may be confounded by patients perceptual styles4 (eg, negative patient influence may influence both physician ratings and self-reported health), suggest the need for alternative ways of assessing physician communication.
Our findings are consistent with our original hypothesis that trained standardized patients provide a more objective (though much narrower) assessment of physician communication skills. The differences in ratings may be due to the biases that each group brings to physician assessment. For instance, patients often self-select physicians with whom they develop a longitudinal relationship. Dissatisfied patients, particularly patients who are dissatisfied with the quality of their interpersonal relationship with their physician, are more likely to change physicians.32,33 Thus, remaining patients represent a selected group in part based on their level of satisfaction with their physicians. Patients may also accommodate themselves to physicians’ interpersonal styles with time. Halo effects may further bias patient assessment; patients who like their physicians are more likely to provide favorable ratings regardless of the aspect of physician performance being assessed. The combination of continued exposure to their physicians’ interpersonal styles, limited exposure to alternative physician styles, and cognitive dissonance (eg, “Would I continue to see a physician who treats me badly?”), all tend to mitigate differences between physicians based on patient ratings.
In contrast with real patients, standardized patients are trained evaluators who have the opportunity to visit multiple physicians. As a result, they may become connoisseurs of communication skills. They are able to assess a physician’s communication skills based on their interactions with many other physicians over a relatively short period and under highly controlled conditions. Their perceptions are relatively unencumbered by prior experience with the physician, sense of indebtedness, or personal investment. They have no agendas or specific expectations for the visit that might affect their ratings.
Others have suggested that standardized patients are a feasible and practical means for assessing physician performance,13,19,31,34,35 although these suggestions are based on standardized patient assessment of specific behaviors rather than global impressions. In either case, however, their use requires considerable efforts to avoid detection by physicians, including surreptitious collaboration with office staff. Such complicity might prove problematic for pay-for-performance purposes, as office staff might tip the physician to the identity of the unannounced standardized patient. Some data, however, suggest that physician detection of standardized patients has little impact on physician performance.36
Although standardized patients have been viewed as the reference standard for assessing physician management of specific problems,13 their ratings are not without limitations. Standardized patients typically rate physicians based on a single first visit devoid of previous context. They are thus more useful for assessing new-patient visits than for assessing chronic care, a fundamental aspect of primary care. Because they have only one opportunity to interact with the physician, standardized patients respond to an important first impression. That first impression may not capture some essential elements of physician care over time. For instance, standardized patients would not be able to assess how physicians would tailor interventions based on close knowledge of patient preferences or family, whether the physician would be supportive during times of emotional or personal distress, or how well they advocate for their patients in complex health systems.37 Ratings derived from white, middle-class standardized patients might differ from those from standardized patients who are members of racial or ethnic minority groups. Finally, there are few data that relate standardized patient evaluations to meaningful clinical outcomes. Despite these limitations, we believe that standardized patients represent a reasonably objective means of assessing specific physician communication skills exhibited under tightly controlled conditions.
Our findings should be considered in the context of the study limitations. First, real patient ratings were elicited previsit, whereas standardized patients completed their rating immediately following their visit. Previsit ratings reflect the cumulative experience of the patient with the physician and provide a general assessment of the physician. Postvisit assessments provide a visit-specific assessment based on more detailed recall of patient-physician interactions. These two types of ratings are only modestly correlated.38 Even though it is possible that higher correlations would have been observed had we surveyed all patients postvisit, our subanalysis using PPPC data suggests otherwise. Moreover, postvisit surveys are more challenging to administer; many instruments are discarded, resulting in potential response bias. As a result, patient ratings, such as the Consumer Assessment of Health Plan Survey, are administered by telephone or mail without regard to the last visit.39 Thus, real patient ratings observed in our study more closely reflect general ratings of physician communication that are currently being used in practice.
Second, standardized patient ratings were based on only 2 different cases. Whether these findings generalize to the range of problems treated by primary care physicians cannot be determined from these data. Third, we obtained a very high response to our patient survey. Response rates to most patient surveys are considerably lower and thus subject to greater response bias.40,41 Last, the physician sample required voluntary enrollment in a study on patient-physician communication. Communication styles of participating physicians may have differed from those who did not participate. It is possible that greater variability and perhaps lower ratings would be seen among a less-selected sample.
For these reasons, it is not possible from these data to determine for certain the reasons for the low correlations between real and standardized patient ratings. It is not clear whether they are primarily due to differences in context (eg, longitudinal relationship vs onetime visit), methods of administration for the HCCQ scale, or real differences in how well these 2 methods assess a key aspect of physician-patient communication, autonomy supportiveness. Further research using comparable types of visits (eg, new patients) and methods (postvisit assessment by real patients) is needed to clarify these important questions.
In conclusion, we found that unannounced standardized patient ratings have better psychometric properties than real patients’ ratings of physicians’ communication behaviors, and that real and standardized patient ratings correlated poorly. These findings raise questions regarding the validity of patient ratings alone for recredentialing physicians or for pay-for-performance incentive programs and the potential usefulness of multiple methods for studying physician interactional behavior.2
Footnotes
-
Conflicts of interest: none reported
-
Funding support: Supported through funding by the Agency for Healthcare Quality and Research (1 R01 10601-A1) and National Institute of Mental Health (5 R01 MH064683-03).
- Received for publication May 4, 2006.
- Revision received August 3, 2006.
- Accepted for publication August 14, 2006.
- © 2007 Annals of Family Medicine, Inc.
REFERENCES



{kind=link}
Jump to section
Related Articles
Cited By...
- Using Standardized Patients to Teach Complete Denture Procedures in Second Year of Dental School
- Measuring Patients' Perceptions of Patient-Centered Care: A Systematic Review of Tools for Family Medicine
- On TRACK: Primary Care Opportunities for Filling Unmet Need
- In This Issue: Real Change Is Real Hard in the Real World